1. 테스트용 테이블 생성
1) 테이블 생성
create table t_tree_test(
no number(10),
name varchar2(30),
parent_no number(10)
);
2) 기본키 지정
alter table t_tree_test
add constraint t_tree_test_pk primary key(no);
3) 자기참조관계 외래키 지정
- 존재하는 레코드만 부모로 사용될 수 있음.
- 부모레코드 삭제시 해당 외래키값 null로 셋팅하여 부모없는 자식이 됨.
alter table t_tree_test
add constraint t_tree_test_fk01 foreign key(parent_no)
references t_tree_test(no) on delete set null;
4) 부모를 의미하는 칼럼에 index생성
create index t_tree_test_idx_01
on t_tree_test(parent_no);
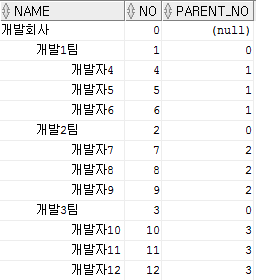
2. 테스트용 데이터 생성
begin
--root 데이터 입력
insert into t_tree_test
(no, name)
values (0, '개발회사');
--2레벨 데이터 입력
for i in 1..3
loop
insert into t_tree_test
values(i, '개발'||i||'팀', 0);
end loop;
--3레벨 데이터 입력
for i in 4..13
loop
if i <= 6 then
insert into t_tree_test
values(i, '개발자'||i, 1);
elsif i > 6 and i <= 9 then
insert into t_tree_test
values(i, '개발자'||i, 2);
else
insert into t_tree_test
values(i, '개발자'||i, 3);
end if;
end loop;
commit;
end;
/
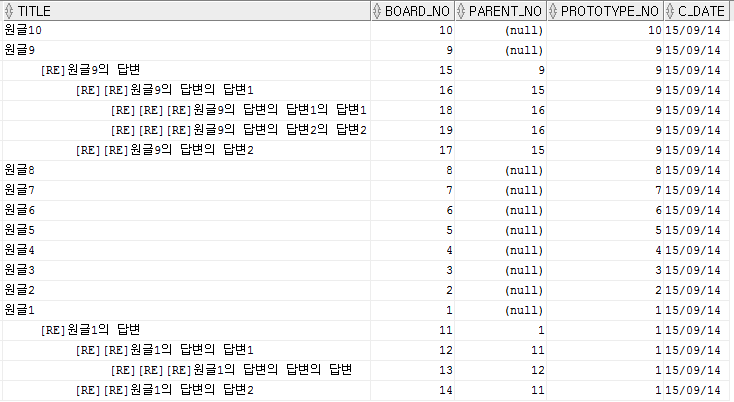
3. 계층쿼리
1) 우선 가장 보편적인 형태
select lpad(' ', 5*(level-1))||name name, no, parent_no
from t_tree_test
where no <> 13
start with no = 0
connect by parent_no = prior no;
- start with no = 0 : 최상위 root를 지정함
- connect by parent_no = prior no : 부모, 자식관계 설정
(자식을 의미하는 항의 칼럼 앞에 prior 지시어를 사용하도록 함.)
- 만약 위와 같이 부모->자식이 아닌 자식->부모 형태로 출력을 원한다면
자식을 root로 사용하게 되는 셈이므로 start with 절에 해당 자식을 지정하도록 하고,
부모를 의미하는 항의 칼럼 앞에 prior 지시어를 사용하도록 함.
※ 계층쿼리의 경우 수행순서는 start with > connect by > where
그렇기 때문에 부득이하게 where조건으로 필터한 뒤에 계층쿼리를 사용하고 싶다면
아래와 같이 inline view 형태로 만들어야 한다.
select lpad(' ', 5*(level-1))||name name, no, parent_no
from
(select name, no, parent_no
from t_tree_test
where no <> 13)
start with no = 0
connect by parent_no = prior no;
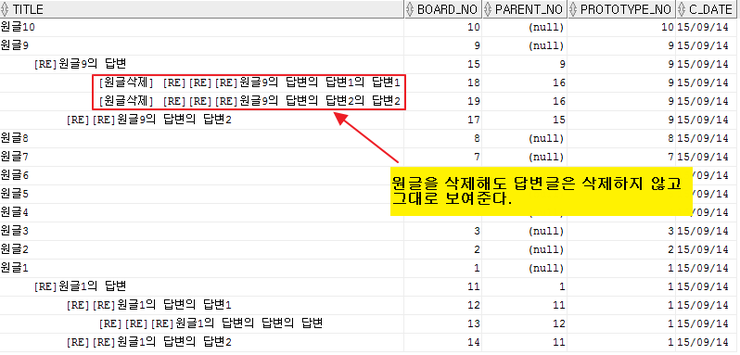
2) 자식들 간에 정렬이 필요한 경우
select lpad(' ', 5*(level-1))||name name, no, parent_no
from t_tree_test
where no <> 13
start with no = 0
connect by parent_no = prior no
order siblings by no desc;
3) 무한루프를 방지
update t_tree_test
set parent_no = 0
where no = 0;
commit;
위 구문을 통해 최상위 root의 parent_no를 자기 자신으로 하도록 한다.
2)번 항목의 계층쿼리를 수행하면 아래와 같은 에러 메시지가 출력된다.
----------------------------------------------------
ORA-01436: CONNECT BY의 루프가 발생되었습니다
01436. 00000 - "CONNECT BY loop in user data"
*Cause:
*Action:
----------------------------------------------------
일반적으로 최상위 root 레코드에서 부모를 의미하는 칼럼 데이터가 자기자신일때
무한루프가 발생하게 되어 위와 같은 에러메시지를 출력하게 된다.
이때는 아래와 같이 connect by 바로 뒤에 nocycle 키워드를 지정해서 무한루프를 방지해야 한다.
nocycle를 적용하게 되면 중복된 데이터 전개될 경우 이를 leaf로 판단하여 더이상 전개하지 않게 된다.
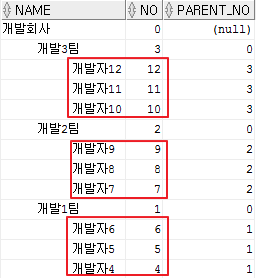
select lpad(' ', 5*(level-1))||name name, no, parent_no
from t_tree_test
where no <> 13
start with no = 0
connect by nocycle parent_no = prior no
order siblings by no desc;
계층쿼리에서 이러한 무한루프가 발생될 수 있는 현상때문에
대부분 최상위 root 레코드에서 부모를 의미하는 칼럼 데이터를 자기자신으로 할당하진 않지만
만에 하나 그렇게 된다면 위와 같이 nocycle 지시어를 통해 무한루프를 회피할 수 있다.
계층쿼리 사용시 기본적으로 항상 위와 같이 nocycle옵션을 포함해서 작성할 것인지
아니면 경우에 따라 사용할 것인지는 본인의 선택이다.
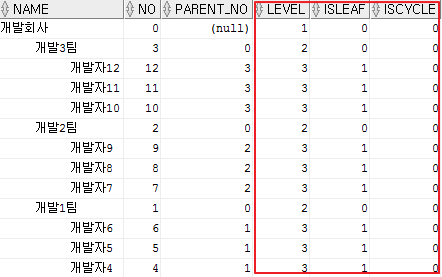
4) 계층 쿼리에서 지원되는 가상 칼럼
select lpad(' ', 5*(level-1))||name name, no, parent_no
,level
,connect_by_isleaf isleaf
,connect_by_iscycle iscycle
from t_tree_test
where no <> 13
start with no = 0
connect by nocycle parent_no = prior no
order siblings by no desc;
- level : 계층쿼리의 레벨을 나타낸다. root(1)부터 1씩 증가되어 할당됨.
- connect_by_isleaf : 해당 row가 leaf 노드인지 아닌지를 나타낸다.(리프:1, 리프X:0)
- connect_by_iscycle : 위에서 설명한 무한루프가 발생하는 발생하는 행인지 아닌지를 나타낸다(cycle:1, nocycle:0)
* 해당 칼럼은 반드시 nocycle 키워드가 지정된 상태에서만 사용가능하다.
cycle가 발생했다면 출력이 불가하다는 말인데 nocycle 키워드를 줘야 결과를 볼 수 있기 때문이다.
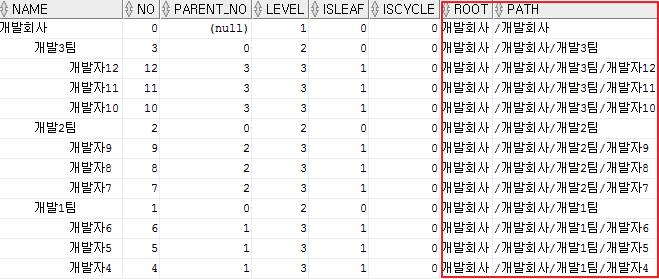
5) 계층쿼리에서 지원되는 함수
select lpad(' ', 5*(level-1))||name name, no, parent_no
,level
,connect_by_isleaf isleaf
,connect_by_iscycle iscycle
,connect_by_root(name) root
,sys_connect_by_path(name,'/') path
from t_tree_test
where no <> 13
start with no = 0
connect by nocycle parent_no = prior no
order siblings by no desc;
- connect_by_root : 계층형 쿼리의 root 항목을 출력한다. 즉, start with 절에서 지정한 노드가 기준이 된다.
connect_by_root(칼럼명)과 같이 루트 노드의 특정칼럼만 출력할 수 있다.
- sys_connect_by_path : 해당 노드에 대해 root노트부터의 풀 경로를 표시할 수 있다.
sys_connect_by_path (칼럼명, '/')와 같이 특정 칼럼을 기준으로 경로를 표시할 수 있다.
두번째 파라미터는 구분값이다.
'밥벌이 > Database' 카테고리의 다른 글
| [Oracle] 제약조건 활성화/비활성화 (0) | 2015.09.18 |
|---|---|
| [Oracle] 외래키 옵션 (0) | 2015.09.18 |
| [Oracle] MERGE 구문 (0) | 2015.09.18 |
| [Oracle] 답변형 게시판 구현 로직 (0) | 2015.09.18 |
| [Oracle] 날짜,시간차이 구하기(년/개월/일/시/분/초) (0) | 2015.09.18 |